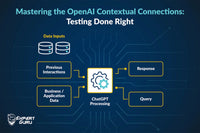
Ever experienced a situation of “Oh, it seems to be real but it’s not?” That’s what we faced while testing our application ExpertGuru, which is ChatGPT-based. Let’s deep dive into how the system works.

Within the intricate architecture of the system, knowledge is amalgamated from three distinct realms, i.e., ChatGPT training data, Business/Application data, and Prompts. A subtle vulnerability arises when the query demands insights which are absent in the business data. In response, ChatGPT, encircled by the constraints of prompt rules, discerns the inadequacy and ingeniously supplements the reply by incorporating relevant information gleaned from its comprehensive ChatGPT training data. This is called Hallucination.
Testing is pivotal here, ensuring the data's validity and truthfulness. Let's delve into the elegant strategies for catching hallucinations:
1. Navigating the challenges of unavailable data
The challenge at hand involves the system autonomously generating data when faced with unavailability. This manifests in the form of fabricated content, spanning links, names, titles, and accompanying descriptions. The system's response to data gaps entails the creation of synthetic information to maintain coherence and functionality, albeit at the cost of data authenticity.
Hallucination-related hurdles at ExpertGuru:
- When our app didn’t deal with product information, it would inadvertently generate invalid product details in response to queries pertaining to products.
- When our app started dealing with product queries within scope but unavailable data, it crafted invalid product titles and descriptions completely by itself.
- We also encountered invalid links in our ad campaigns.
General testing solutions:
- Test cases on available data and verifying that the output is accurate/true.
- Test cases on unavailable data.
- Ex. Complete data unavailability – Domain Expert
- Scope: Contact lens
- No data regarding the product or brand is injected. It is just a domain expert bot to educate people about contact lenses and related information like material, types, colour, time, etc.
- Query: I want to buy coloured contact lenses for power -0.5; show me some products.
- Response: “Sure, for your coloured contact lens with power -0.5, here are some of the links to buy…abc.com....”
- Note: We never injected any product-related information, so the tester should verify these kinds of responses present with links, brands, product descriptions, etc.
- Ex. Data availability – Missing data
- Scope : Electronics wearables
- Data is available for products ear pods, neck bands, and smart watches.
- Upon a thorough examination of data, it was found that the above are available in a large variety and standard colours. Now a tester should approach for missing but related aspects like missing colour, missing features, etc. Let’s consider a green colour watch is not available since it’s not a standard colour for watches.
- Query: Show me some smartwatches in colour green.
- Response: “As per your preference for smartwatches in colour green, here are some products: P1- Sea green colour BT calling watch….”
- Note: We don’t have green or any closer colour to green smartwatches available in our collection.
Insights:
- The tester should meticulously analyse both the data and prompts. Using the prompts as a guide, they should identify the data relevant to our application that is absent in the provided dataset and formulate test cases accordingly.
- Also, the tester should adeptly utilize the existing data to construct relevant test cases. This approach ensures a comprehensive assessment of the system's overall functionality. The validation of available data holds immense significance, serving as a crucial gauge for evaluating how well our application aligns with the provided data.
2. What if bot is configured to provide both thrilling and insightful responses?
The present challenge entails a delicate balance, experiencing the inclination to overpromise in response generation. The quest for allure poses a potential hazard as there's a fine line between enhancing attractiveness and assigning disproportionate importance to loosely related data in crafting responses.
Hallucination-related hurdles at ExpertGuru:
- Only a small bit of description meets user query needs; the rest of the data is irrelevant to serve queries, but the response is very convincing.
General testing solutions:
- Testing that the bot sticks to the data and does not form malicious data over loosely related data. Thus, it should be validated to ensure that the response is totally in sync with the data and every bit and piece should be factual.
- Test case for within scope but unavailable data. The below example depicts how to verify.
- Ex.
- Scope: Snacks store
- Available data is around various kinds of Chinese snacking items and customized toppings available. Toppings include vegetables, sauce type, etc.
- Query: Suggest to me something healthy from your store.
- Response: The response is only around vegetables and very overpromising for healthy eating like “As you are looking for something healthy, we provide you with a range of various vegetables as toppings which can help you add nutrition to your diet even while snacking. What’s your mood for today? Here is the menu....”
- Note: Title/Descriptions about available items never mentioned about healthy eating/snacking.
Insights:
- The tester should consider low-priority data or associated data and make general query test cases over these data. Like in the above, vegetables within the toppings section are not part of the main menu data, i.e., various types and names of Chinese cuisines.
3. What if data is available but there are differences in some of the data categories?
In this instance, the challenge arose as data underwent edits to align with user queries. Unlike the previous scenario, a greater alignment with the queries was achieved, with only a minor section found to be disconnected. This disconnected portion was seamlessly replaced to meet the query requirements.
Hallucination-related hurdles at ExpertGuru:
- For product recommendation queries, our product title was edited. Only a word or two were replaced not all.
General testing solutions:
- Test cases where around 80-90% of queries matched available data while the rest was disconnected from the data.
- Ex.
- Scope: Electronics
- Data: Only laptops available
- Query: "Show me some available desktop computers with a fast processor and long battery life for gaming."
- Response: "Here are some desktop computers with a fast processor and long battery life suitable for gaming as well." + the product title of laptop computer was edited by the desktop computer for response + product images are of the laptop.
- Note : In the above example, the text response aligned appropriately with the given query, but editing at the data level was conducted to generate a response that lacked accuracy. Furthermore, since product images are sourced from the database, they reflect the actual data. Consequently, there is a discrepancy between the text response and the displayed products.
Insights:
- The tester should scrutinize the intricacies of the data, creating test cases that focus on data details, especially in queries that emphasize numerous data particulars. Subsequently, one should skillfully tweak a word or two for comprehensive testing which makes a data unavailable case.
Conclusion
The tester should have a know-how of the data injected into the application. The general steps to help in creating test cases involve:
- Prompt reading: Prompts are rules which influence the content of ChatGPT replies. The quality and specificity of the prompt can significantly impact the generated output. Also, hallucinations can be handled via prompts only, so it is the responsibility of the tester to consistently update the prompt engineer with any encountered issues.
- Business/Application data knowledge: The tester should have a deep knowledge of application data and its variety, types, related data, related but unavailable content, etc. So, here, the responsibilities of the tester involve deep data examination and then test case creation.
- Testing thoroughly could be a game changer: The verification and validation of responses are highly important as this application deals with large data handling.