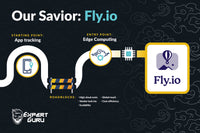
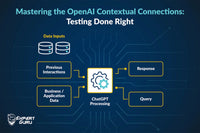
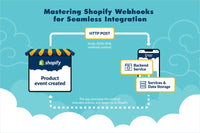
Proficient prompt engineering is akin to engaging in a compelling conversation with a large language model.
So, what is “prompt engineering”? How is it relevant? Why is it necessary to "learn" English, the language from which Large Language Models (LLMs) have derived their knowledge during training?
Are there any challenges? What can be the challenges? Or even better, since this Generative AI (GenAI) space is in its early stage (or rather advanced version of the OGs), do we know and understand all the challenges? How sure are we? Or are we sure?
We at ExpertGuru started with similar questions. And today? We have the same questions with confidence.
So, basically, prompt engineering has now become a key practice in the field of AI, particularly with LLMs like ChatGPT or GPT-3. It involves crafting queries that guide these models to produce specific, high-quality outputs. By adjusting the prompt's detail level, we can significantly influence the AI's response, balancing breadth, and get useful responses. Effective prompt engineering can help greatly, from generating codes to creating engaging content.
“With great power comes greater responsibilities.” – Peter uncle. “With great prompt comes greater opportunities.” – Ms. Anonymous
How do we choose a “good” prompt?
Writing any prompt is heavily dependent on the use case and has a human bias to it as well. However, there are a few thumb rules that if we follow, we can write prompts efficiently (pretty much).
a. Use a simple sentence structure for instructions.
b. Use the “not” word not so frequently.
c. Use proper markers.
Ha! Again, for us, we experiment with different types of prompting techniques and always choose the simplest ones because, in real time, we want minimum hazards in production. Anyway, if I had a special technical checklist, I would always look for the following:
- Is it very clear? It must be straightforward, minimizing misunderstanding. No ambiguity.
- Is it targeted? It should have a properly mentioned task or information required.
- Is it conversational enough? For the cases, if prompts are phrased in a way that mirrors natural human conversation, they add up to the language model’s responses.
- Is it getting enough context? We should provide the relevant information required to make the interaction as meaningful as possible.
- Does it have some character? We should add guidelines to give AI good character traits: humble, honest, and concise. It can enhance the assistant's likability over time.
- Is it staying on topic? Staying relevant to topics is essential for any system.
For generative AI models like ChatGPT, several problems can arise from the prompts used to guide the AI's responses. Some of the most notable issues that we faced included:
1. AI Hallucinations: This terrifying term refers to instances where AI goes on and generates outputs that are factually incorrect or entirely fabricated. And these responses look very promising and close to the real world. This happens due to the AI's nature to deduce data patterns without the ability to dissect the truth, leading to plausible but inaccurate content. And this can lead to poor customer support or inaccurate research findings.
2. Token Limit Constraint: A significant technical limitation I faced was the token limit, which is the maximum number of pieces of information (tokens) the model can process at one time. This includes both the input (the user's prompt) and the output (the AI's response)! For example, consider this scenario: When ChatGPT had a token limit of approximately 4,096 tokens for input and output combined, affecting how much information can be included in a single interaction. This constraint can particularly impact tasks requiring the processing of large amounts of information, such as generating product recommendations from an extensive list. The token limit restricts the amount of product information that can be included in the prompt, potentially leading to incomplete analysis, response truncation, and reduced efficiency.
How did we tackle them?
To address these challenges, we used several strategies. Like a ton, experiment. A hit and trail. Here are the major things that worked for us:
- We improved our input context quality: We added clear, concise, and well-structured context in our prompts. It helped to minimize the likelihood of hallucinations.
- Set that temperature to zero: Yes 0. A 0 temperature value ensures that the responses could stay highly predictable (basically not so random).
- We strictly defined the AI's role and limited the scope of responses it could give: Clearly outlining the AI model's intended use and its limitations can help in reducing irrelevant or hallucinatory results. We used a very good role prompt and a few checks, along with simple rules, for ChatGPT to follow. Something like this:
- We did continuous testing and refinement: A rigorous and ongoing evaluation of our system was crucial to detect and rectify hallucinations, ensuring the AI's outputs remained relevant and accurate over time. We added tons of rules and checks for each time.
- We implemented custom algorithms to manage token limit responses:
a. Summarizing the larger documents: So, this method works very much like a map reduce algorithm. We divide a large piece of document into reasonable chunks and summarize each chunk. Now we reduce these chunk summaries to one. Understood? Here’s how it goes:
i. Divide: Split the document into smaller sections for easier handling.
ii. Summarize: Extract key points from each section to create individual summaries.
iii. Reduce: Merge these summaries into a single, comprehensive
b. Information Extraction (IE): This is an interesting approach where we focus on pulling out specific, relevant information from document chunks based on predefined criteria or questions. Here’s how it works:
i. Identify Key Information: We determined the types of information we required. Something like super concise and very specific facts relevant to our domain.
ii. Chunking: Similar to the first method, divide the large document into manageable chunks. However, instead of summarizing, you scan each chunk for the specific information identified in the first step.
iii. Aggregation: Compile the extracted information from all chunks into a structured format. For us, it was a very comprehensive list for our system to consume further, but one can always process it in a different format, depending on the end-use. This aggregated data represents the most relevant information pulled from the entire document.
Both the above methods, of course, require multiple AI responses, which add latency to our systems. As we continue to navigate the evolving landscape of AI, prompt engineering undoubtedly plays a pivotal role in shaping our interactions with these powerful models. Whether for creative endeavors, data analysis, or developing sophisticated AI assistants, the principles of prompt engineering remain at the heart of effective and meaningful AI engagement. At least for now.